1. 통계 기본지식
통계란?
현상을 나타내고 있는 데이터로 부터 '유용한 정보'를 도출하여 의사결정에 도움을 줄 수 있게 하는 것.
→ 통계를 보고 인사이트를 도출할 수 있음.
Q) 우리나라 국민의 정치적 성향을 알기 위해 통계자료를 만든다면, 어떤 기준이 필요할까?
모든 국민을 전수조사 할 수 없으므로 왜곡되지 않게 표본을 뽑아 샘플링한다. 표본조사를 시행한다면 오차는 존재할 수 밖에 없음.
통계학적 수용가능한 오차 범위는 5%로, 오차가 5% 미만(신뢰수준 95%)인 통계자료 일 경우 유의미한 값으로 본다.
A) 통계자료를 확인할 때 유의수준(오차범위)가 5% 범위 내에 도출된 자료인지 확인해야한다.
따라서 ''유의수준(오차범위) 5% 범위 내에서' 대한민국 41.7%가 xx당을 지지 한다'라는 인사이트를 도출했다면, 믿을 만한 자료라고 판단한다.
2. 표본으로 전체를 설명하는 검정 통계학
가설 검정
- 귀무 가설: 기존의 사실과 같은 것. 내가 주장하는 것의 반대되는 가설. 기각시켜야 할 가설. 내가 주장하는 것.
- 대립 가설: 귀무 가설의 반대
예1: 무죄추정의 원칙
형사가 범인을 잡을때 판사가 판결을 내리기 전까지 '무고한 사람'임. 법정에서 증인을 통해 무죄를 증명했다. → 대립 가설이 기각됨으로 귀무 가설이 성립됨
예2: 학원 수료시 취업율
우리 학원을 수료했을 때, 수료하지 않은 상태와 같다. 하지만 수료했을때 취업율이 월등히 높았다. → 귀무 가설(기존의 사실과 같은 것)의 기각됨으로 대립 가설이 성립됨
p-Value < 0.05 이라면, 귀무가설 기각 및 대립가설 채택
p-Value란? 1종 오류를 범할 확률
: 0.05 이상이 되면 결과를 신뢰할 만하다고 볼 수 없다.
: 0.01로 보는 경우도 있는 것처럼 값이 정해진 것이 아님.
: 무조건 작은 값이 좋은 것이 아니라 0.05 범위 내에 들면 되는 값. (pass or non pass)
*1종 오류 vs 2종 오류
1종 오류: 귀무가설이 참인데 기각하는 경우.
2종 오류: 귀무가설이 거짓인데 기각하지 않는 경우.
1종 오류란? 귀무가설이 참인 경우(내가 잡은 사람이 무고한 사람일 것)를 기각 한다면 대립 가설을 채택해야한다 → 내가 잡은 사람이 범죄자였음 (참이라고 믿은 사실을 거짓이라고 해야하는 상황)
귀무가설, 대립가설, p-value는 반드시 알아야 함.
핵심 요약정리
1. 모집단, 전수조사
2. 표본, 표본조사
3. 유의수준(오차한계):5%
4. 신뢰수준:95%
5. 가설(귀무가설, 대립가설)
6. p-Value<0.05, 대립가설 채택
3. 기술 통계(시각적 통계를 같이 보는 것이 효과적임)
기술 통계를 알아야 하는 이유는 히스토그램, 변동계수를 확인한 데이터 기반의 의사결정할 수 있음. 통계와 그래프를 모두 그려 판단해야할 필요가 있다.
산술평균: 총 합의 변수 n개로 나눈 값. (보통 평균값이라고 하면 산술평균을 의미)
중앙값: 가운데 위치한 값. 개수가 짝수인 경우 중앙의 가운데 위치한 2개를 더해 반으로 나눈 값.
최빈값: 가장 많이 불린 값. (빈도가 높은 값)
편차: 하나의 데이터 값이 평균에서 얼마나 떨어져 있는지에 대한 값.
편차의 제곱:
분산:
표준편차: 값의 변동성을 파악할 수 있음.
왜도: 데이터가 대칭을 이룰수록 왜도 값은 0, 데이터가 한쪽으로 치우칠수록 양수 또는 음수
첨도: 데이터가 세로로 뻗칠 수록 양수. 분산될 수록 음수 (음의 첨도면 변동성이 큰 시장)
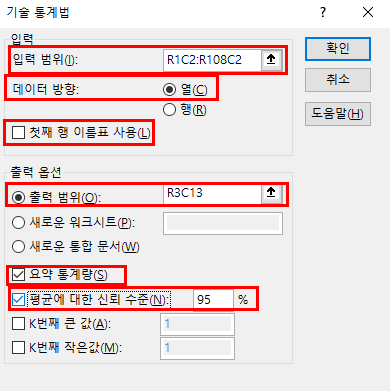
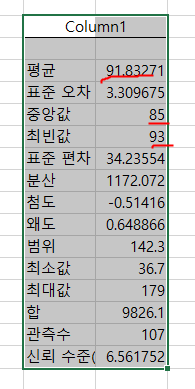
1. 평균의 함정: 임원의 급여를 연봉평균을 계산하면 전체 평균이 높아지기 때문에 중앙값과 최빈값을 고려해야한다. 따라서 중앙값, 최빈값 고려해야할 필요가 있다.
2. 편차, 표춘편차, 분산의 이해
공식을 알 필요가 없고 손으로 계산할 필요도 없지만 개념은 이해해야한다.
- ☆편차: 하나의 데이터가 '평균'에서부터 얼마나 떨어져 있는지 알 수 있는 값. 예) 한국에서 임금 100만원, 말레이시아에서 임금 100만원은 다르다. 평균값과 편차를 확인해야함. 편차 확인시 변동계수 확인이 필요함.
변동계수: 표준편차를 산술평균으로 나눈것
- 분산: 분산(variance)은 관측값에서 평균을 뺀 값을 제곱하고, 그것을 모두 더한 후 전체 개수로 나눠서 구한다. 즉, 차이값의 제곱의 평균이다.
단, 제곱을 하기 때문에 값이 상당히 크므로 잘 쓰지 않는다. (단, 그래프의 분포도를 알기 위해 사용.)
- 표춘편차: 값의 변동성을 파악할 수 있다.
예) 코스피 지수 1분기 지수가 표준편차가 500임. 2분기에 1000이 나왔다. 안정적인 시장은? 1분기. 표준편차가 커지면 중심에서 멀리 떨어져 있는 값이기 때문에 안정적인 시장을 파악 가능.
3. 왜도와 첨도



왜도: 값이 왼쪽으로 쏠려있는지, 오른쪽으로 쏠려있는지
왜도가 양수라면 그래프의 산이 좌측으로 몰려있다.
왜도가 음수라면 그래프의 산이 우측으로 몰려있다. 예) 평균 사망자 나이대

첨도: 얼마나 위 아래로 퍼져있는가
첨도가 양수일때 위로 솟아있고
첨도가 음수이면 아래로 퍼져있다.
(양수일수록 평균값이 몰려 있다)
4. 상관분석 correlation analysis


삽입 탭 - 차트에서 드롭다운 메뉴 선택하여 분산형 차트 유형 선택하면
산점도 그래프를 확인할 수 있다.(오른쪽)
분포된 형태를 보고 양의 상관계수를 나타내고 있구나~라고 확인할 수 있다.
EXCEL의 CORREL 함수를 사용하여 상관계수를 확인할 수 있다.
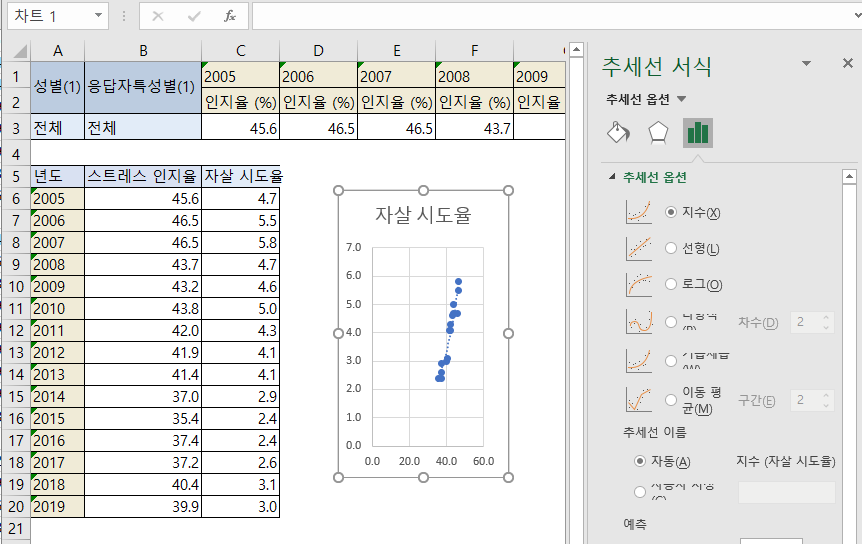
상관관계와 인과관계는 다르다. 상관관계가 높은 것과 인과관계는 전혀 상관이 없다.
아주 써먹을 만하고 쉬운 데이터 분석이라 빅데이터에서 가장 많이 활용된다.
맥주와 기저귀
가설 예시: 30대 남성이 기저귀 심부름을 하면서 맥주를 사간다.
구매 패턴을 가지고 맥주와 기저귀의 상관결과가 아주 높게 나옴. 마트 진열을 기저귀와 맥주를 가까이 두었더니 매출이 300%증가.
1인당 치즈 소비량과 침대시트에 얽혀 죽은 사람의 수
상관계수가 엄청나게 높지만, 그야말로 원인과 결과와는 아무 상관이 없다라고 해석해야한다.

아이스크림 구매율과 범죄율은 상관율이 높지만, 인과관계가 없다. (오류)
불쾌율과 아이스크림 구매율은 상관율이 높고, 인과관계가 있다.
불쾌율과 범죄율은 상관율이 높고, 인과관계가 있다.
그렇다면 인과관계를 구하기 위해 어떻게 해야할까?
인과성이 충족되기 위해서는 아래와 같은 세가지 조건이 필요하다.
- 공변성
- 같이 움직이는 경향이 있음을 확인 할 수 있어야 함.
- 예: 업무만족도가 높으면 성과가 높다. 업무만족도와 성과는 함께 움직이는 경향이 있다 → 의심 가능
- 같이 움직이는 경향이 있음을 확인 할 수 있어야 함.
- 선후관계
- 시간의 우선성
- 예: 데이터역량 수업을 들었을때 데이터 역량이 향상되었다. → 의심 가능
- 시간의 우선성
- 비허위성★
- 허위성이 없어야 함. 외부의 개입 통제 조건 필요.
- 또 다른 인과성을 줄 수 있는 다른 통제 필요
- 업무만족도가 높았던 이유는 사실은 직원의 급여가 높았기 때문이더라. 급여라는 제 3의 변수 통제 필요.
- 허위성이 없어야 함. 외부의 개입 통제 조건 필요.
!!상관계수 : 상관계수를 보고 어떻게 해석할지가 중요함.
· 두 변수 사이의 관계(상관관계)를 반영하는 수치
· 기술통계 값의 범위는 -1과 +1 사이 (절대값으로 강도를 나타낸다. 따라서 -0.7과 0.5를 비교 해봤을때, -0.7을 상관관계가 더 크다고 봐야한다. 1에 가까울 수록 상관관계가 크다.)
-1< 상관계수(p) < 1
-1은 완전한 음의 직선 상관 관계(상관성이 크다)
-0.8 강한 음의 상관관계
-0.3 약한 음의 상관관계
0은 직선 상관관계가 아님(기준)
0.3 약한 양의 상관관계
0.8 강한 양의 상관관계
1은 완전한 양의 직선 상관관계(상관성이 크다)
상관계수 유형
· 두 변수가 같은 방향으로 변하는 상관관계: 직접 상관관계 또는 양의 상관관계
· 예) 공부를 많이 하면 시험 점수가 오를 것이다.
· 두 변수가 반대 방향으로 변하는 상관관계: 간접 상관관계 또는 음의 상관관계
· 예) 운동을 많이 하면 몸무게는 감소할 것이다. / 시험 시간이 줄어들면, 문제를 틀릴 가능성이 높아진다.





5. 평균비교
평균 차이만 가지고는 두 그룹의 차이를 알 수 없다.
T 분석을 통해 두 그룹의 유의미한 차이를 알 수 있다.
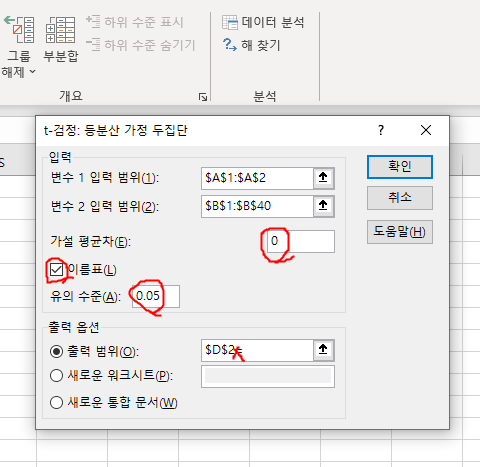
T 검정 등분산을 할 때 가설 평균치에는 귀무가설을 넣어야 한다.
쌍체는 보통 사전/사후의 차이가 있다는 가설을 확인할 때
6. 회귀분석


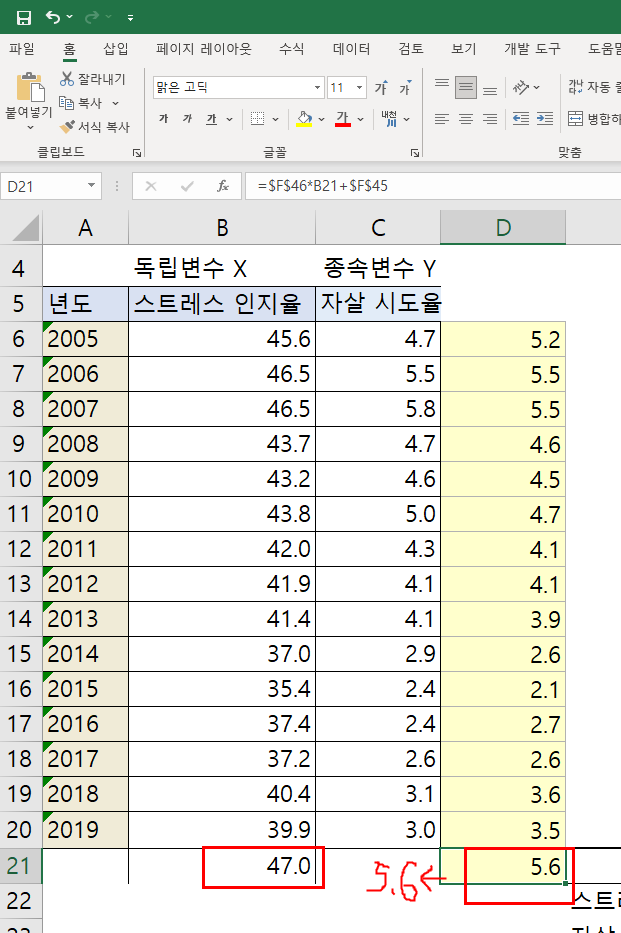
연봉이 높아지면 연차가 올라간다?
연차가 높아지면 연봉이 올라간다!
Y X
Y=AX+B
회귀분석하기 위해
1. 독립변수 (x: 연차)
2. 종속변수 (y: 연봉)


결정계수(R스퀘어 값): 결정계수가 높을수록 큰 인과관계를 가진다.
결정계수를 확신하기 전 단계 존재:
1. 분산분석의 유의한 F가 0.05보다 작아야 유의미한 결과
2. 독립변수의 P-Value 값 확인(0.05 이하)
3. 잔차 합계가 0에 가까운지
y=ax+b(a는 기울기, 계수)(b는 y절편) -> 엑셀 사용시 =누르고 x계수 누루고 F4
7. Supervised Learning 데이터 분류 or 회귀 / Unsupervised Learning 이상값 감지 or 그룹화 / Reinforcement Learning 강화학습
머신러닝 종류:
분류, 회귀
분류: 사진을 주고 강아지인지, 고양이인지 구분하게 하는 것 (구글 티쳐블 머신)
이상값 감지, 그룹화
강화학습
: 딥러닝에서 사용하는 좋은 결과가 나올때까지 학습하게 함.
: 자전거 처음 탈 때, 보조바퀴 달고, 넘어졌다가 결국 잘 달리는 것처럼
8. 다중회귀분석


조정된 상관계수는 오차범위를 줄여서 나온 결과값이므로 유의할 필요가 있다.

꼭 알아야 하는 것:
결정계수(회귀계수)는 100%(1~100) 인과성이 있다고 보고 92%의 인과성이 있다라고 해석해야한다.
잔차(오차) : 오차이기 때문에 0에 가까우면 유효한 데이터라고 본다.
다양한 독립변수가 있을 때 상관관계가 있는 독립변수끼리 상관관계가 있는 것을 고르는 것이 중요
다중회귀분석 후 독립변수의 계수를 확인해보면 어떤 독립변수가 가장 영향을 끼쳤는 지 확인 가능
표준오차보다 2배 넘는 잔차를 가지는 아웃라이너를 찾아내는 것도 필요, 왜냐하면 아웃라이너를 바꾸는 것까지 고려해야 하니깐
문자로 된 데이터는 조건열 이용해서 숫자로 변환, 독립변수에 3가지 이상의 독립변수 넣기. 상관관계가 낮더라도 인과관계가 입증 될 수 있다.
9. 표준화(데이터 전처리)
집단 a, 집단b 의 값이 달라서,
p value 가 너무 높거나 달라서 사용이 불가능하다고 생각된다면
충분한 자료가 필요하고 내가 알고 싶은 집단의 표준화, 평균, 표준편차를 구한다
... 조사 더 필요함..


웹에서 다운로드 받은 엑셀의 숫자를 엑셀에서 사용할 수 있는 숫자로 변환하기
value 함수
숫자 선택 후 느낌표 클릭 -> 숫자로 변환
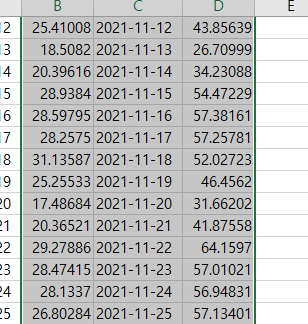
이렇게 클린한 결과를 확인할 수 있다.
'기획 > 데이터 리터러시' 카테고리의 다른 글
| 기술통계 개념 (0) | 2021.12.27 |
|---|---|
| 상관계수 값이 낮은 이유: 차원의 저주 (0) | 2021.12.26 |
| 엑셀 파워쿼리 피벗 열, 열 피벗 해제하기 / 열분할 시 따옴표 구분 방법 (0) | 2021.12.17 |
| 엑셀 파워쿼리 조건열 설정하기 (0) | 2021.12.16 |
| 엑셀 파워쿼리 엑셀파일, 폴더 연동하기 (0) | 2021.12.16 |

댓글